What happens outside of the project folder?
So far, we’ve focused on how the Project Folder is set up to help you go from data to final product. There’s a lot of work, however, that has to happen outside of this set-up. While things like funded grant applications, relevant protocols and data management plans, naming conventions, etc. can all be kept together with a project in the Background directory, there are other aspects (literature, lab notebooks, etc.) that can be relevant across multiple projects. In reality, you will need to develop a network of interconnected workflows to see a project from start to finish.
As an example, I’ve outlined my workflow in schematic form here, and describe some of the key tenets below. Before going any further, know that these workflows are highly individual. What I describe is something that I’ve found works for me; you might benefit from something similar, or something completely different. Explore the (many) options out there!
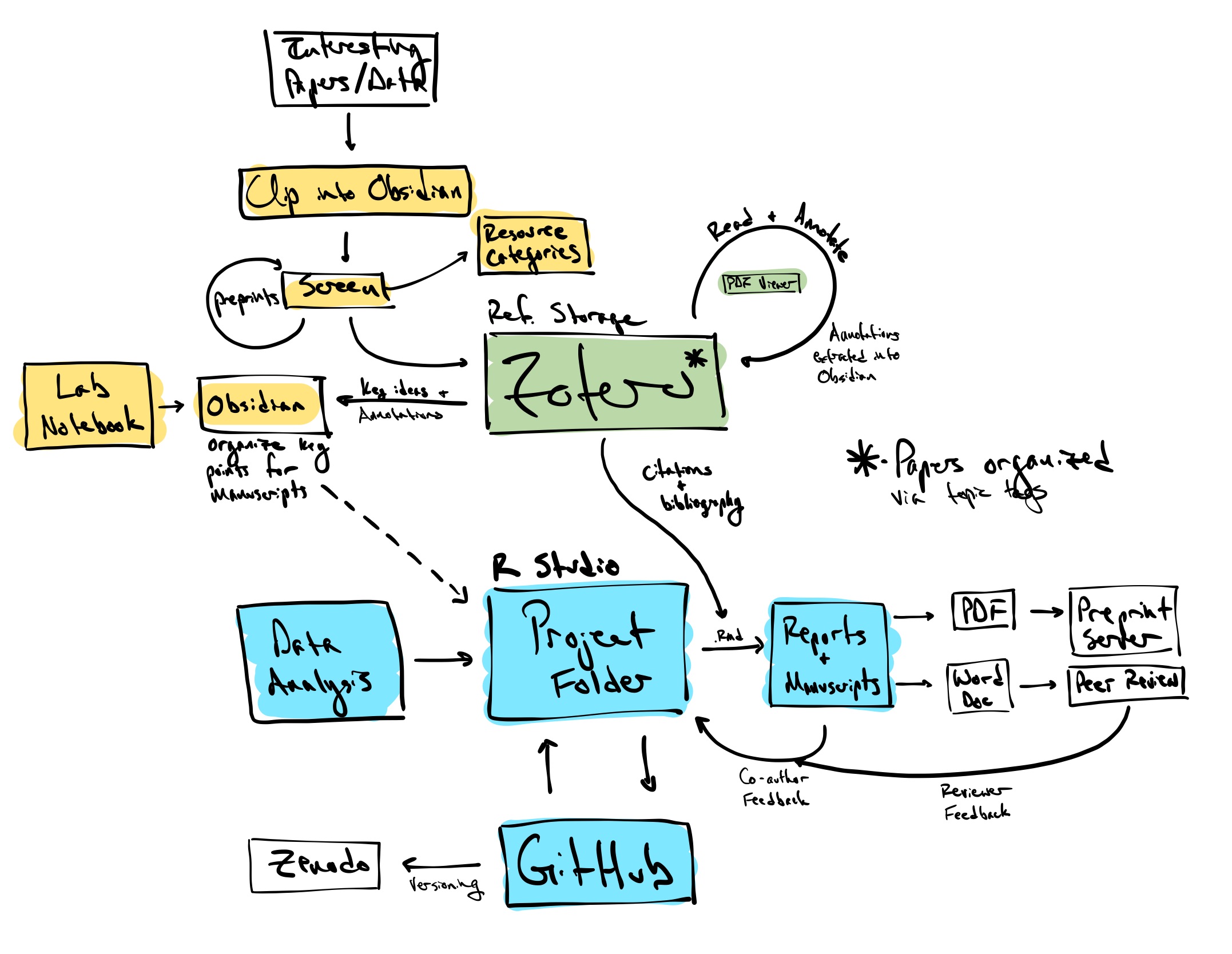
Work flow priorities
A major part of research is reading literature. For better or worse, each day sees a flood of new papers published across any number of scientific journals. This is where the day-to-day workflow starts for me. You need some system for capturing, sorting, organizing, and annotating these papers. Ideally, your system will also help you recall information (or at least be able to find it again when you go looking for it) and make connections between key points gleaned from different papers. Each of those steps (capturing, sorting, organizing, annotating, and synthesizing) are the focus of myriad programs, tools, approaches, and philosophies. Before you dive into everything that’s out there, spend some time thinking about how you work, and what elements would actually help you get stuff done. Do you want something that is simple and streamlined? Or do you prefer all the bells and whistles so you can customize things to your liking? How much time per day do you intend spending on each of these steps? Be realistic here - there’s no point in setting up a system that requires a little time each day to work if you know you’d prefer to spend more time at less frequent intervals, or vice versa.
My personal workflow emphasizes five things:
Quick capture - I need to be able to quickly flag a paper, data set, protocol, news article, etc. when I see it. The key here is being able to grab anything and everything I see that might be relevant to past, present, or future work. I rely on a combination of Google Scholar and Web of Science alerts for general topics of interest, authors, and citations to certain key papers; social media; and more targeted, project-specific literature searches to collect (potentially) relevant papers. In addition to Google Scholar and Web of Science, OpenAlex is a great resource. ResearchRabbit and other tools like it might also be worth exploring. My general impression of these “AI powered” tools, however, is that they are by no means a replacement for traditional search strategies. By all means, though, change my mind.
When I come across something interesting, I send it to a single ‘inbox’ in my Obsidian vault (using this great web clipper tool). Remember my priority here is speed of capture, so I don’t worry too much about judging utility, relevance, or value on the spot. Once or twice a week, I’ll sit down and sort through the inbox. Not everything ends up being relevant or useful, but I don’t mind having to screen extra stuff in order to be more confident that I’m not missing important papers or resources.
A robust centralized organization - After collecting all these resources, I need a robust system to organize everything. I’ll eventually have to find them when they’re needed. This is easy when something relates to a project I’m currently working on, but can be tricky when something is relevant (or might become relevant) for future projects. I also prefer that these systems be ‘centralized’ (i.e. - one collection of resources accessed for multiple projects, rather than an individual, independent collection for each project).
When sorting through the inbox, non-paper resources (data sets, tutorials, pedagogical resources, etc.) are screened out and organized by topic in a series of notes in Obsidian. I also screen out preprints to keep track of work that look promising but hasn’t been published yet. This leaves published papers, which are screened for relevance, utility, interest, etc.
Papers I want to store for later use are sent to Zotero, again using a helpful web clipper tool. I prefer Zotero over some of the other major reference managers because it’s open source and developed by a non-profit organization. Once a paper is in my Zotero library, I’ll tag it with relevant topics and in some cases add a note to the entry with more specifics about how I envision using this reference. Zotero lets you create ‘Saved Searches’, which are essentially folders that update when new, relevant entries are added - I use these to maintain collections on general topics of interest. This strategy seems to hit the right balance for me between project-level organization of papers (being able to find it based on the topics tagged) and keeping things centralized (I only ever have one copy of a paper in my library).
As an added bonus, you can link your Zotero library to RStudio, an use their nice in-text citation interface to import references and bibliographic information to .rmd files!
Easy annotation - I know that I am really vulnerable to the collector’s fallacy (the notion that gathering information is the same as learning the information). I also know that I’m less likely to read something in a timely manner with more complex workflows. That being said, I want the effort that goes into reading a paper to “pay off”; specifically, I want be able to easily find the notes that I took when I return to a paper, rather than having to re-read the entire thing over again. I lose handwritten notes too easily, and I get too distracted by one long word document / excel file of notes. My solution is to keep notes and annotations stored alongside the PDFs of the papers. Zotero (version 6 and onward) includes an excellent PDF reader that I use to read and annotate papers. Most importantly for me, notes and annotations from Zotero can be quickly pulled into Obsidian, creating a single note for each paper. I add a brief summary of key aspects of the paper like the aims, methods, results, synthesis of the paper, along with a ‘how am I going to use this’ section - importantly, these summary sections are re-written in my own words, not quoted verbatim. This is a useful self-check of my understanding of the paper, and helps me to remember some of the key aspects of the paper (or at least, helps me remember that I read something about Topic XYZ, even if I can’t remember the exact information). While this is a pretty involved step, setting up my paper notes like this keeps the bibliographic information, reading notes, and my own thoughts on the paper all together in the same place. Using Obsidian also means that it’s easy to to link the paper notes to multiple projects.
Making connections across resources - Some of the most interesting ideas stem from connections between two seemingly unrelated topics. Regardless of the method used to take notes, you will need to keep the notes you take organized. Much like how RStudio and the project folder helps you work in R, Obsidian is a text editing environment that helps you work with markdown text files. One of the distinguishing features of Obsidian, though, is the use of internal links. These links between notes allow you to quickly tie together anything in your collection - reading notes, lab notebook entries, project summaries, grant plans, etc. etc. This not only makes it easier to see patterns and make connections within a topic, but it let’s you start to make connections across project/topic boundaries.
As discussed elsewhere, I also use Obsidian as a digital lab notebook (and require you to do the same). The ability to use templates makes things like setting up experiments, recording the health of cultures, and keeping track of daily activities a little easier. And because it uses markdown files, you don’t have to worry about not being able to access data across systems.
Integration - There’s no single perfect app that does everything I want to aid my workflow. I also don’t want to be reliant on a bunch of different apps and software (I know I am too easily distracted by the grandeur of these complex workflows to get any actual work done with them). Over time I’ve settled on the workflow described here, which relies on just a couple, relatively streamlined programs (Obsidian, Zotero, and RStudio) that integrate nicely with each other, and feed well into the Project Folder setup that’s been the focus of the rest of this site. Additionally, while relying on centralized systems, there’s no barriers to the flow of information and insight from outside to inside the project folders. For me, this is the most important aspect; to be able to go from a broad, centralized network of resources to highly specific application in individual projects.
With this said, however, remember that while you work in this lab, you’re essentially required to use all three of these programs already
Final Words
Remember, the system I’ve outlined here is what works for me (or at least what worked for me as a early-stage processor in 2025). Everyone works in different ways, and this might change for you over time. I’ve laid things out here to provide a single example. You can take whichever components (if any) work for you and then explore your other options to fill in the gaps in your workflow. Whether you are piecing together an initial workflow or refining what you’re already working with, my main piece of advice is to focus on how you work, not what you’re working with. Be honest with yourself about what you actually need in order to stay engaged with the literature, to develop your own ideas, and to eventually compile and share these ideas with others. The temptation to add whatever new and shiny software is popular at the time into your workflow will always be present. And sometimes this new software might be useful for you. But in order to keep making progress on your work (and it is the work that really matters, not the workflow), you’ll be best served by thinking carefully about your own personal workflow priorities. This will probably be an iterative process. You might not land on something right away. But as you learn more (and learn more about how you learn best), you should be able to build a workflow that helps you feel excited about the material you’re working with!